Problem
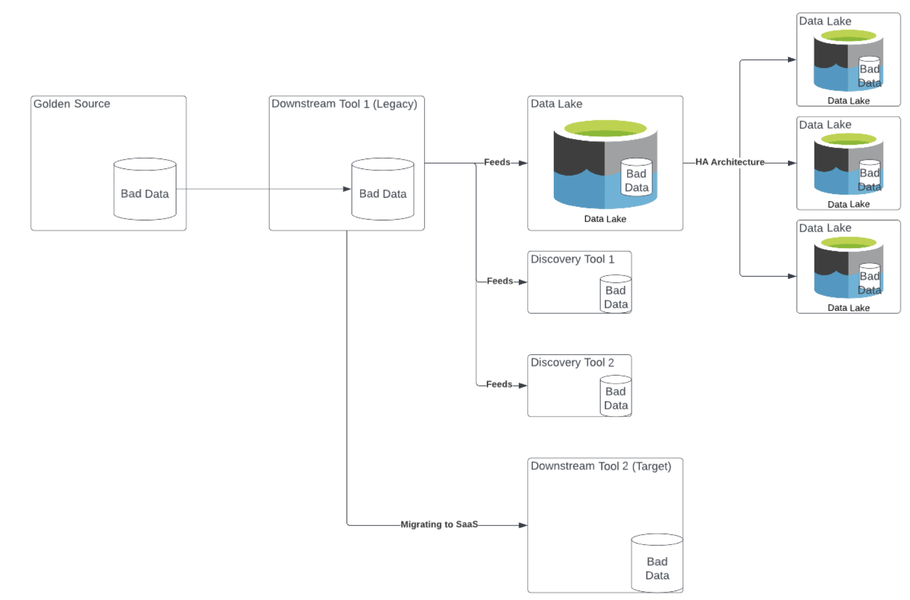
Bad* data in a system of origin (or Golden Source system) propagates to multiple downstream systems. If these downstream system are built on Highly Available (HA) architecture the bad data progates again multiple times. While old or stale data in a system may seem innocuous or even trivial, it’s existance may have a larger impact then you realise.
In highly complex interconnected systems, data flows between systems regularly. These data flows can take the form of:
- real-time streaming of data between systems
- daily or nightly feeds between systems
- system backups
- data replication across instances of a system for redundancy and failover scenarios
There may also be tool migrations or upgrades in progress, further complicating the spread of bad data. “We’re migrating from Golden Source 1 to Golden Source 2, so we are not allowing any more changes to Golden Source 1. We’ll clean it up later.” Effectively this says that we will live with the virus, and the spread of bad data throughout our systems.
Also, there is the Fear Of Deleting Data (FODD), making it even more difficult to “kill” the virus. (Follow us to read our upcoming Anti-Pattern #3 for more details.)
While the management of old, stale or redundant data may be a low priority issue, due to the Bad Data Virus, the problem may be a magnitude larger than you realise in terms of:
- cost of storage
- cost of data ingress and egress
- speed and performance of the systems storing this data
- user experience
- cost of carbon emissions. This is possibly the most important issue of all. Data Pollution causes Carbon Pollution.
The problem of storing bad data may seem minor at team scale, but is serious at enterprise scale, and very serious at national and global scale.
Solution
To avoid spreading the Bad Data Virus, bad data needs to be cleaned where it originates – in the Golden Source system. Any cleaning of the bad data in downstream systems is potentially wasted activity, as the Golden Source will still have the bad data so it will reappear in downstream systems after the next feed or data transfer.
Due to the Fear of Deleting Data (FODD), it is highly unlikely and possibly dangerous for data to be maintained and cleaned manually. Data maintenance policies must be automated.
Automated Data Maintenance
Data Ingress
In order to stop bad data getting into our systems, we need to design automated guardrails for data entry.
For example, all data should have an owner. Data should not be allowed into the system without an assigned owner. The owner should be a product, service or team. The owner should NOT be an individual. Individuals come and go, but the product and/or service should be long-lived. If data has an owner, it is easier to ask the owner what to do with the data. If data does not have an owner, it is very difficult to determine the importance or usefulness of the data, so the data will likely remain in our systems due to FODD.
Data Storage
In order to keep our data stores clean, we need to define automated clean up policies based on well publicised data retention policies. Automated data maintenance policies provide comfort to the teams and services because the policies have been approved and are well understood. This eliminates FODD.
For example, we may decide that “Snapshot” (or non-persistent) binary artifacts from our continuous build systems only need to reside in our Artifact Repository systems for 3 months before they can be deleted. Once this policy is in place, snapshot artifacts are automatically cleaned up and developers know that these artifacts won’t last long. If they need persistent, long-lasting artifacts they should flag the artifacts as “Release” artifacts. When these policies are in place and well understood, delivery teams will embed their own processes to ensure important artifacts are persisted properly.
See this Expert View article (part 1) for more examples of data retention policies in DevOps tools.
The Bad Data Virus infects many of our IT systems. To improve efficiency, costs and most importantly the carbon emissions required to store and transfer old and stale data, implement automated data maintenance policies.
*if we wanted to be more polite we could say stale data or old data, but unnecessary storage of data leading to unnecessary use of power (carbon) and water is bad.

Head of DevOps
Devoteam UK

