Problem
Automated processes running at high frequency generate large volumes of data – code, log files, build artifacts, change requests, etc.
In the legacy world of technology, many software lifecycle processes were manual and occured irregularly – compiling, testing, deploying, attending Change Approval Boards (CAB), raising changes, closing changes, etc. These processes would happen possibly a couple of times a day, possibly once or twice a week or month.
In the new automated DevOps world of technology, these processes are automated through CI/CD pipelines. Many of these processes (compile, test, deploy) run after every code check-in, or may run at regular intervals like every 5 minutes.
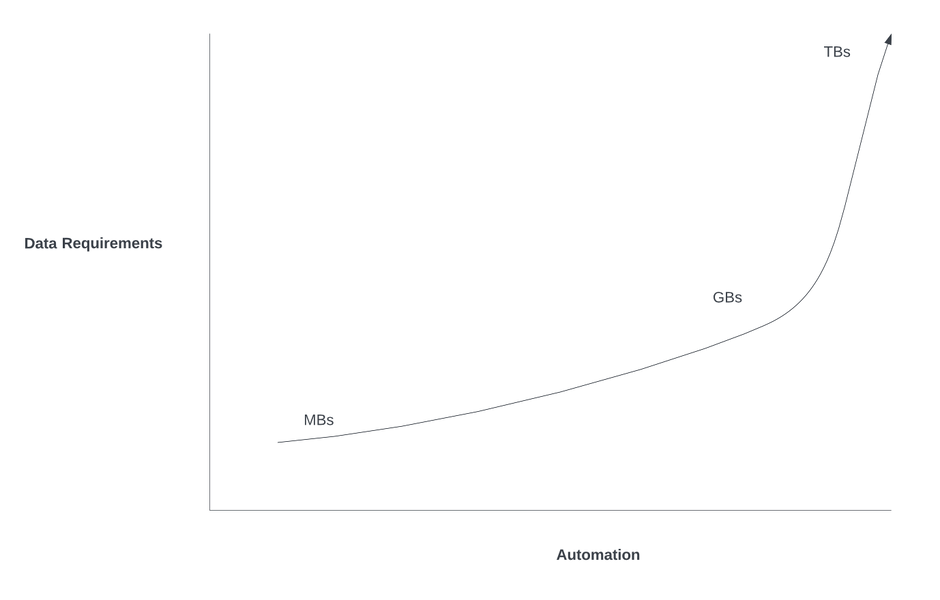
So the processes are now running a magnitude more frequently, and therefore the outputs of those processes (the data) grow a magnitude more quickly.
If not managed properly, this data will grow exponentially and may soon overwhelm the tools that store the data, or the SaaS budgets that pay for storing and transferring the data. e.g.
- Artifact repositories such as JFrog’s Artifactory or Nexus.
- Git repos such as GitLab, GitHub or Bitbucket
- Change management tools such as ServiceNow or Jira Service Management
- Logging and other monitoring tools like Splunk, Datadog, or New Relic.
On-premise DevOps tools become bloated, slow, and difficult to maintain leading to poor user experience. For Software-as-a-Service (SaaS) based DevOps tools this leads to large usage bills.
Solution
- Ownership
All data should have an owner. Unowned data is problematic. If the data is unowned, it is difficult to determine who is responsible for it, if it needs to be presistent, if it is important, etc.
All data should be tagged with the owner. That owner should be a product, service, application or team. The owner should not be a person. People come and go. Products and services should be long lived.
- Automated Data Maintenance
Well defined data retention policies and data cleanup policies are essential. If you don’t have data retention and cleanup policies, you need them. Now. And they should be automated.
Financial Services organisations are particularly conservative around data retention so have very strict data deletion policies. Mention deleting data in a live financial services system and people get very nervous. “If in doubt, leave it (the data) in.” It’s difficult to get in trouble if you leave the data “as is”. If you do attempt to clean up bad or irrelevant data and make a mistake, you can find yourself in all sorts of trouble. So most people play it safe and do not delete data, no matter the relevance, volume or quality. This is the Fear of Deleting Data (FODD).
What that means in practice is that once data gets into a production tool (specifically a DevOps production tool) it will often never be deleted. Data maintenance is at the bottom of the backlog. Data retention and deletion policies are not high priority. Priorities are to get tools up and running. But lack of these data policies soon becomes expensive. Without controlling the data, the tools become bloated, sluggish, hard to upgrade, hard to maintain, and provide a poor user experience.
If data retention policies are automated, people feel safe and secure. Well-defined automated policies are far safer than manual processes. If data retention/deletion policies are not automated they will almost never happen, due to FODD.
Let’s look at some of key DevOps processes in terms of data management:
- Automated Builds: In CI (Continuous Integration) pipelines, build logs typcially are not needed within hours or days of the build process. Yet some build data may be important and need to be kept as evidence for a longer period. Determine what builds are important and what logs require long term storage, versus frequent build data that are not important and can be regularly cleaned.
- Artifact Management: For CD (Continuous Deploy or Delivery) pipelines, differentiate temporary deploy artifacts (or “snapshots”) that are created on every invocation of a deploy pipeline, versus deploy artifacts that are production release candidates. Snapshots should be deleted regularly. Release artifacts will often exist indefinitely. Deployment artifacts can be hundreds of megabytes, or even gigabytes in size, and the pipelines that build these artifacts can run many times per day. If you have no cleanup policies all data will exist forever and your tools can grow to 10s and 100s of terabytes of data.
- Task Tracking Systems: Evaluate the importance of data stored in task tracking systems like Jira. Is this data business critical? Do we need to store virtual post-it notes for the next 7 years? (Historically we threw away the paper post-its at the end of the sprint!)
- Source Code Repositories: Implement strict cleanup policies for source code repositories (e.g., Git repos). Regularly remove unowned code, personal projects, playground code, proof of concepts, and duplicate or forked code. All code stored long term must have a valid owner (i.e. a product or service). This helps maintain a clean and organized codebase.
- Logging and Monitoring: Huge volumes of data can be produced by logging and monitoring systems. This data needs to have a well-defined lifecycle. The data can be very important, particularly if investigating incidents or outages. But there comes a time (usually quite quickly) when the data is no longer relevant or needed.
- Service Management: Automated processes that integrated with service management tools, such as ServiceNow, can raise large numbers of automated change and request records. Automated self-healing systems may raise large numbers of automated incidents. These automated request, change and incident records have volumes magnitudes larger than previous manually created records.
With all DevOps tooling there is a potential to be overwhelmed by data. This data needs to be managed through automated retention/deletion policies.
Make data management policies a core element of your automation activity. The upfront costs are relatively small, often just a configuration change. However the benefits are substantial in terms of improved tool performance, cost reduction, carbon emissions, user experience and overall productivity.
Find out more in Part #2 of this article, read it here.

Head of DevOps
Devoteam UK

