
Comparing human-generated data and machine-generated data and their implications for the AI industry
Introduction
Data is the essential ingredient that makes AI work. Without data, there is no learning, no intelligence, no innovation. But not all data is created equal.
In this blog, we will explore the importance of data for AI and review the different types, such as human-generated data and machine-generated data. We will compare their different characteristics, benefits and challenges, and how they affect the AI applications that rely on them.
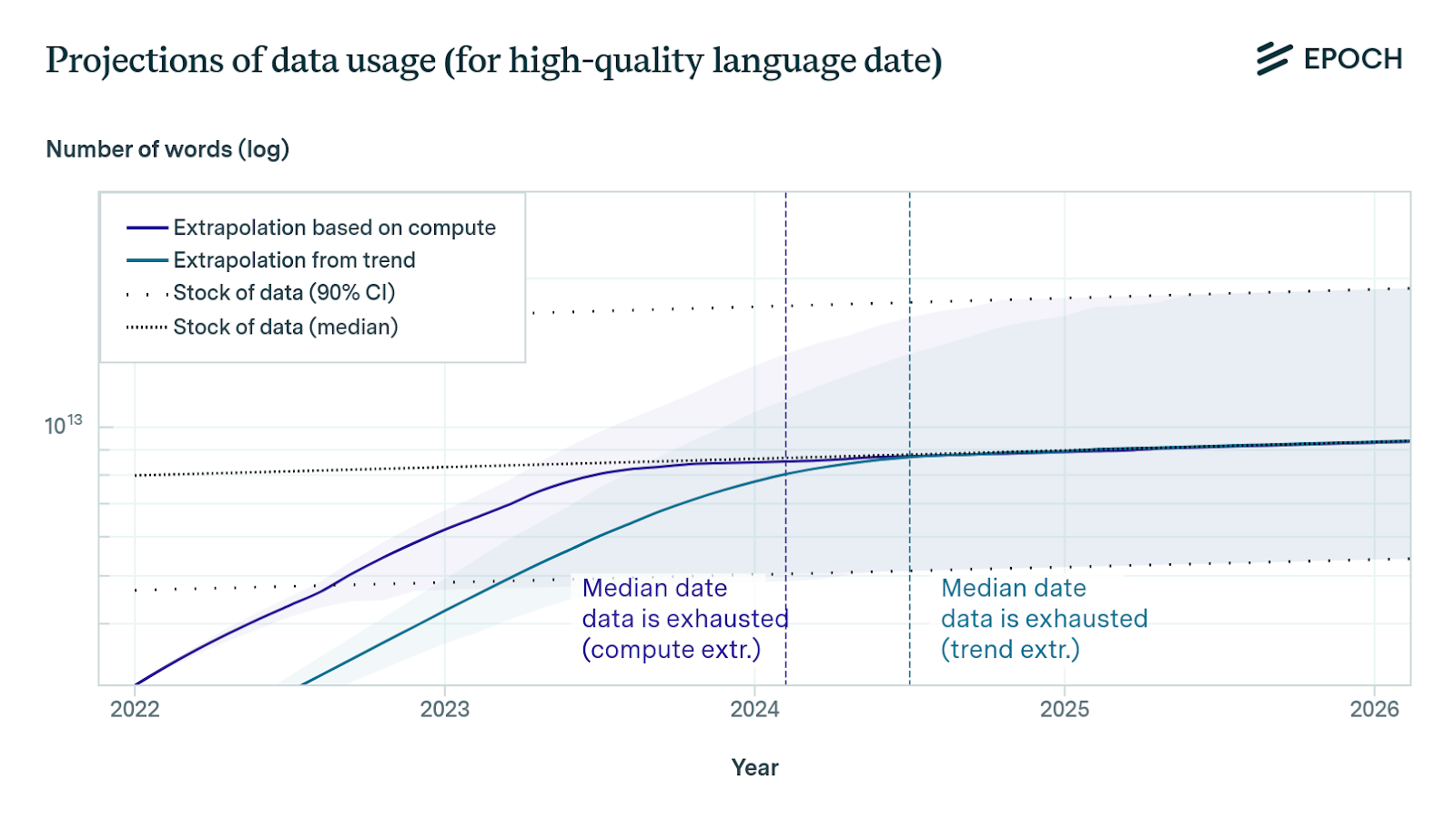
We will also discuss the implications of these types of data on the future of AI, and why we need to be prepared for a possible data shortage. According to research conducted by Epoch AI, they highlight trends that see the end of new data for training AI models. At the current pace, we will probably run out of human-generated data to train AI models between 2030 and 2050.
What does this mean for the AI industry and the society at large? How can we overcome this challenge and ensure the sustainability and scalability of AI?
Read on to find out more.

Data for AI
Data is as relevant for AI as fuel is for a car. Without data, AI models cannot make progress, perform, or optimise. However, not all data is created equal. Data comes in various forms, depending on whether it is produced by humans or machines. They have different characteristics, benefits, and challenges.
Human-generated data
Human-generated data is created by people through human action, as opposed to machine learning or other artificial means. This can include anything from text to social media posts to pictures and videos. Human-generated data is often unstructured, meaning that it does not follow a predefined format or schema. Human-generated data is valuable for AI applications because it reflects human behaviour, preferences, opinions, emotions, and creativity. It can also cater to exclusive requirements that machine-generated data cannot fulfil, such as facial recognition or speech recognition. However, human-generated data also has some drawbacks, such as:
- It is costly and time-consuming to collect, process, and label.
- It is prone to errors, biases, and inconsistencies.
- It is limited by human capacity and availability.
Machine-generated data
Machine-generated data is produced automatically by a computer process, application, or other mechanism without the active intervention of a human. This can include anything from web server logs to sensor readings to financial transactions. Machine-generated data is often structured, meaning that it follows a predefined format or schema. Machine-generated data is useful for AI applications because it is abundant, accurate, consistent, and scalable. It can also fill the gaps in human-generated data, such as generating synthetic data or augmenting existing data. However, machine-generated data also has some challenges, such as:
- It is difficult to interpret, understand, and explain.
- It is sensitive to privacy, security, and ethical issues.
- It is dependent on the quality and reliability of the machines and algorithms that generate it.
Brief comparison and contrast
| Aspect | Human-generated data | Machine-generated data |
| Source | People | Machines |
| Type | Unstructured | Structured |
| Volume | Limited | Abundant |
| Quality | Variable | High |
| Cost | High | Low |
| Speed | Slow | Fast |
| Diversity | High | Low |
| Relevance | High | Low |
Implications for AI applications
The choice of data type for AI applications depends on the purpose, context, and requirements of the project. There is no one-size-fits-all solution. In some cases, human-generated data is more suitable, such as when the AI model needs to understand, interact, or even emulate humans. In other cases, machine-generated data is more appropriate, such as when the AI model needs to optimise, monitor, or automate processes. In many cases, a combination of both types of data is optimal, such as when the AI model needs to enhance, complement, or verify human data.
Some examples of AI applications that use different types of data are:
- Generative AI: this is a branch of AI that aims to create new content or data from existing data, such as images, text, music, or code. Generative AI often uses both human-generated data and machine-generated data. For instance, DALL·E, an AI system that can generate realistic images and art from a description in natural language, uses human-generated data as input, and machine-generated data as intermediate representations.
- Sentiment analysis: This is a branch of AI that aims to identify and extract the emotional state or attitude of a person or a group of people from text, speech, or images. Sentiment analysis mainly uses human-generated data, such as social media posts, reviews, comments, or surveys, as input. However, it can also use machine-generated data, such as lexicons, ontologies, or models, as resources or tools.
- Fraud detection: This is a branch of AI that aims to prevent, detect, and mitigate fraudulent activities or transactions in various domains, such as banking, insurance, ecommerce, or healthcare. Fraud detection primarily uses machine-generated data, such as transaction records, network logs, or sensor readings, as input. However, it can also use human-generated data, such as customer profiles, feedback, or reports, as supplementary or contextual information.
Data is essential for AI, but not all data is the same. Human-generated data and machine-generated data have different characteristics, benefits, and challenges. Depending on the purpose, context, and requirements of the AI application, one type of data may be more suitable than the other. However, a combination of both may be more optimal. Therefore, it is important to understand the differences and tradeoffs between human-generated and machine-generated data, and to choose the best data type for the AI project.

Is the data running out?
The growing push toward training larger models means a greater need for data. Research from the company Epoch AI suggests that, at the current trends, we will run out of human-generated data to train AI models between 2030 and 2050. The research from Epoch AI also analyses the limits of data, especially for large language models and computer vision models. But the main finding of the research is that the current trend could pose a serious challenge for the AI industry and the society. This will require new innovations in data efficiency and diversity.
Conclusion
We have discussed the role and value of data for AI, and how different types of data have different characteristics, benefits and challenges. We have also explored the implications of these types of data for the AI industry, and how they affect the performance, versatility and sustainability of AI applications.
We have learned that data is a critical resource for AI, but also a limited and uneven one. We have seen that, according to research from Epoch AI, we may face a data shortage in the near future, and that we need to find new ways to generate, collect, label, and use data more efficiently and diversely.
This blog has given you some insights and perspectives on the importance of data for AI. Please join us in the next blog, which highlights the AI race in 2024 and major developments that facilitate more growth and development of AI.
If you want to learn more about this, you can get in touch here.

