
Introduction
Recently, I wrote a Whitepaper giving an overview of Conversational Artificial Intelligence (AI), the relationship to Large Language Models (LLMs), and their potential use cases. If you’ve not yet read the whitepaper, I’d recommend doing so; to get a grounding in the technology and to understand this new article more effectively.
The white paper discussed a possible use case of an AI ecommerce chatbot, where MuleSoft was used as the integration layer to access the relevant LLM. As I proposed that use case, I feel it incumbent upon me to build a Proof-of-Concept (PoC) to demonstrate the capability of this use case.
From this article, “Integrating MuleSoft with OpenAI: Building an intelligent chatbot”, you’ll discover that the software tools provided by MuleSoft are highly capable of integrating with this technology, allowing the development of solutions that utilise AI. You’ve got the backbone of the infrastructure for these solutions using the core architectural concepts of API-Led Connectivity and Application Networks, combined with Anypoint Platform for full-lifecycle API Management iPaaS.
Architecture and Design
I proposed the building of an e-commerce chatbot. However, re-evaluating that original idea, I’ll modify the aim slightly. For the PoC, I feel it’s better to build a generic and easily adaptable chatbot that uses public or easily accessible services to provide the functionality. As this is a generic solution, it can easily be extended to use different services to create a custom-tailored chatbot or data analysis tool for any specific task.
So, the Brief:
Build a Smart chatbot (i.e. LLM-based) accessible over the internet from a Web Browser or a Personal Assistant hardware device (e.g. Amazon’s Echo/Alexa). The chatbot should use conversational AI technology to interact with a user and have accessibility features allowing it to use audio hardware (i.e. microphones and speakers).
That’s what’s required; how’s it going to be achieved?
Starting with the conversational Language Model. Most of you will be aware of the two most well-known LLMs currently in the spotlight; OpenAI’s ChatGPT and Google’s Bard, and as ChatGPT has a publicly accessible API, that’s the one we will use for this PoC.
For Automatic Speech Recognition (ASR), OpenAI’s Whisper Speech-to-Text (STT) service will interact with a microphone. It will capture and transcribe any spoken prompts/requests from a user. OpenAI doesn’t have a Text-to-Speech (TTS) service, so Google Translate’s free TTS API will be used (sufficient for this PoC).
One final Requirement that mustn’t be forgotten is the ability to interact with a Personal Assistant device to access the chatbot. With Amazon’s Echo device, it is possible to create custom functionality called Alexa Skills. A Skill will be developed to integrate with the chatbot and make it accessible from any such device.
Before getting into the Build, the first stage is to take a deeper look into those services and technology, to understand them and, technically, how to call the respective APIs.
OpenAI
Two services from OpenAI: ChatGPT (Conversational AI) and Whisper (STT), will be used:
- ChatGPT is an LLM based on OpenAI’s Generative Pre-trained Transformer technology (GPT-3.5). The model has been tuned for a more conversational style of interaction, ideal for a chatbot.
The Chat endpoint is:
https://api.openai.com/v1/chat/completions
This POST endpoint accepts JSON and contains the text prompt from the user.
As this API is well documented, there is no need for further detail apart from providing a link to the API Reference page.
- Whisper is OpenAI’s Speech-to-Text service that uses voice recognition technology to transcribe voice captures. Any captures will be used as input to the chatbot.
The Transcriptions endpoint is:
https://api.openai.com/v1/audio/transcriptions
This POST endpoint accepts multi-part data indicating the path to the relevant audio file.
Again, this API is well documented, so you only need a link to the API Reference page.
However, before proceeding further, you should note:
- There is a limit to the combined size of the request/response that ChatGPT will process. OpenAI uses the concept of Tokens to measure this size – ChatGPT has a limit of 4097 tokens (and as a very rough Rule of Thumb, 100 tokens equals 75 words). Once this limit is exceeded, ChatGPT will stop responding. However, for this PoC, the requests and responses will be kept well below that limit.
- ChatGPT is conversational, but the API doesn’t store any conversation history. The narrative must be resubmitted on each interaction to allow the LLM to stay in context. However, bear in mind that such resubmissions count towards the token limit! Again, for a PoC, all dialogues will be kept well below the threshold.
Though note that GPT-4 (OpenAI’s next iteration of the GPT series of LLMs) already has a much higher token limit. Additionally, further research aims to raise the threshold substantially higher, effectively removing this limit for most use cases.
As stated earlier, this TTS service is sufficient for this PoC. But note there’s no documentation on the API or how to use it (other than anecdotal evidence on developer-oriented sites such as StackOverflow).
To document what is known about this API for the necessary purposes of this PoC.
https://translate.google.com/translate_tts?ie=UTF-8&tl=en-UK&client=tw-ob&q={text}
It is a GET endpoint with all parameters passed as query parameters in the URL. The two essential parameters are tl which specifies the type/accent of the voice, and q, which is the text to be spoken.
Note Google does have a much more advanced TTS API – but it’s not free. Hence, the reason for using this one in the PoC.
Alexa Skills
The documentation detailing how to build an Alexa Skill and how to call APIs from those Skills is extensive. There are also many blogs and posts to follow. As this article aims not to cover building such functionality, it will not be detailed here. All that is needed is a relatively simple Skill that can call out to APIs.
Python Flask
The chatbot GUI is also simple; a Python Flask app using HTML. This article isn’t concerned with Python web development, so it isn’t covered. However, the documentation is extensive, and several Python libraries (e.g. Streamlit) already exist that can be used to build chatbot interfaces if preferred.
MuleSoft
If we re-focus on MuleSoft and apply the principles of API-Led Connectivity, this is what a possible High-level Application Network will look like.
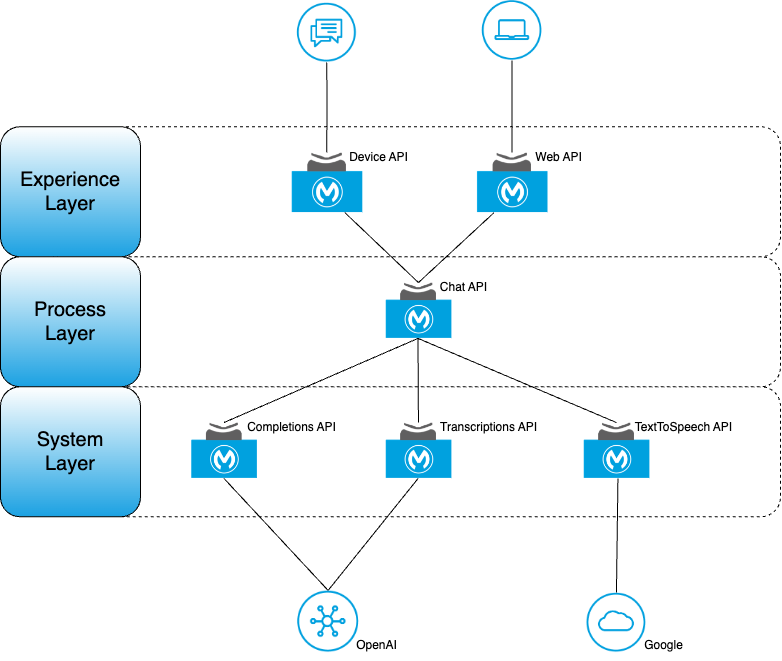
If you’ve not yet done so, I encourage you to read the Whitepaper to understand more about MuleSoft and concepts such as API-Led Connectivity.
Building the Chatbot
With the Design in place, the Build can begin. Let’s demo the necessary features and specific usability aspects.
Initial Loading Screen
First, this chatbot needs a persona relevant to its use case. As this is just a generic chatbot, it’ll take on the persona of ‘Max, the Mule’ – a helpful personal assistant.
To do this, a System Message has to be passed to ChatGPT, which initiates the interaction and tells ChatGPT how to act.
{“role”: “system”, “content”: “You are Max the Mule, a helpful assistant.”}

There is a slight delay on initial loading as the screen makes an API call to ChatGPT to get the chatbot’s initial greeting (as with all Web Sites making an API call). So while that is happening in the background, the screen is only partially rendered. It contains some static images, which have been added for aesthetics – to give the chatbot a certain ‘look and feel’. These can be customised or replaced as required. And, of course, the screen displays the obligatory Loading Wheel.
Loaded Chatbot
Once the initial call to ChatGPT is complete, the screen is then fully rendered.
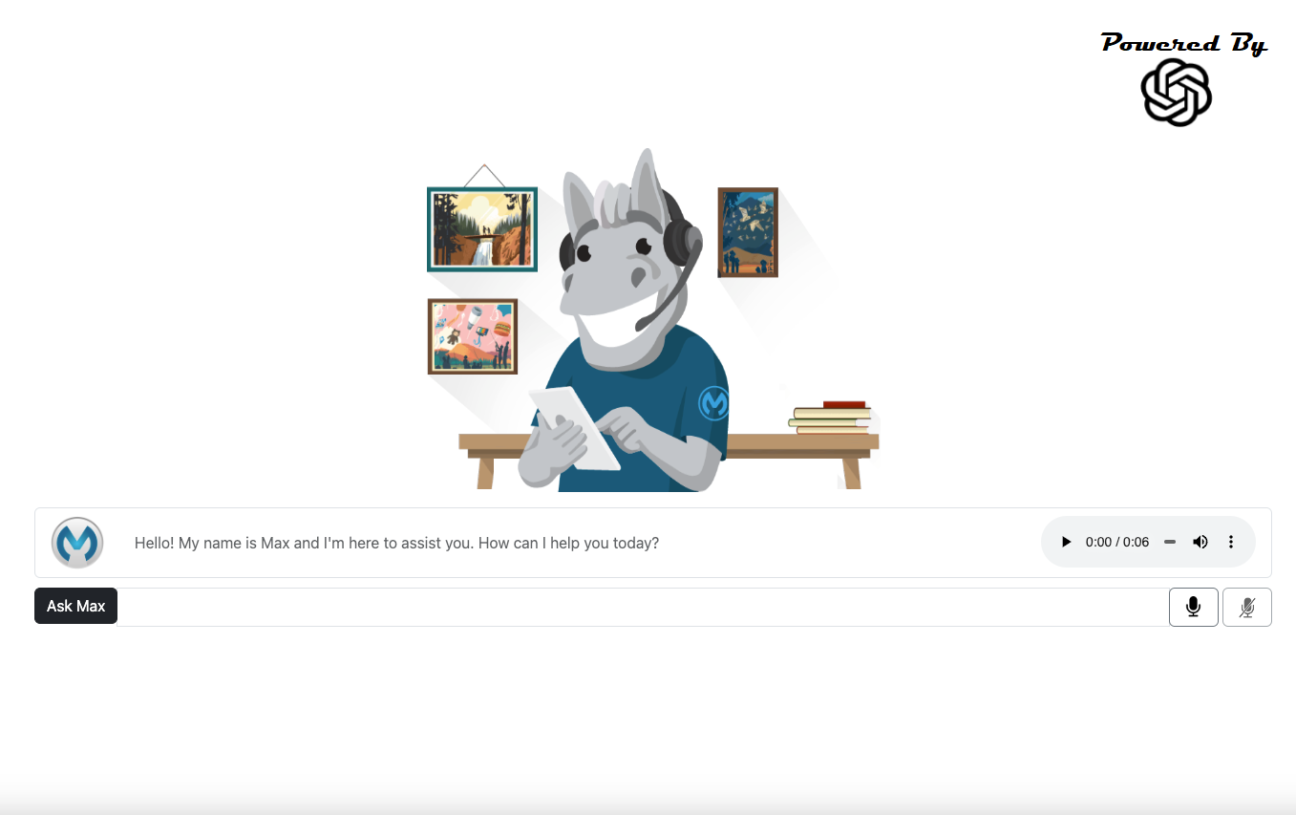
This initial screen contains several different objects:
- There is the opening greeting from Max – remember, the chatbot was given an initial persona by passing an appropriate phrase to ChatGPT.
- There are buttons provided for accessibility; see the audio control button to give the chatbot a voice (to play back the response). Remember, Google Translate’s TTS service was used for this.
- Finally, user input buttons and a text entry box are at the bottom of the screen.
Asking the First Question
The screenshot below shows that the chatbot has picked up the user’s question and added it to the conversation history. The chatbot then responded to it. Again, audio controls have been given to replay the response verbally.
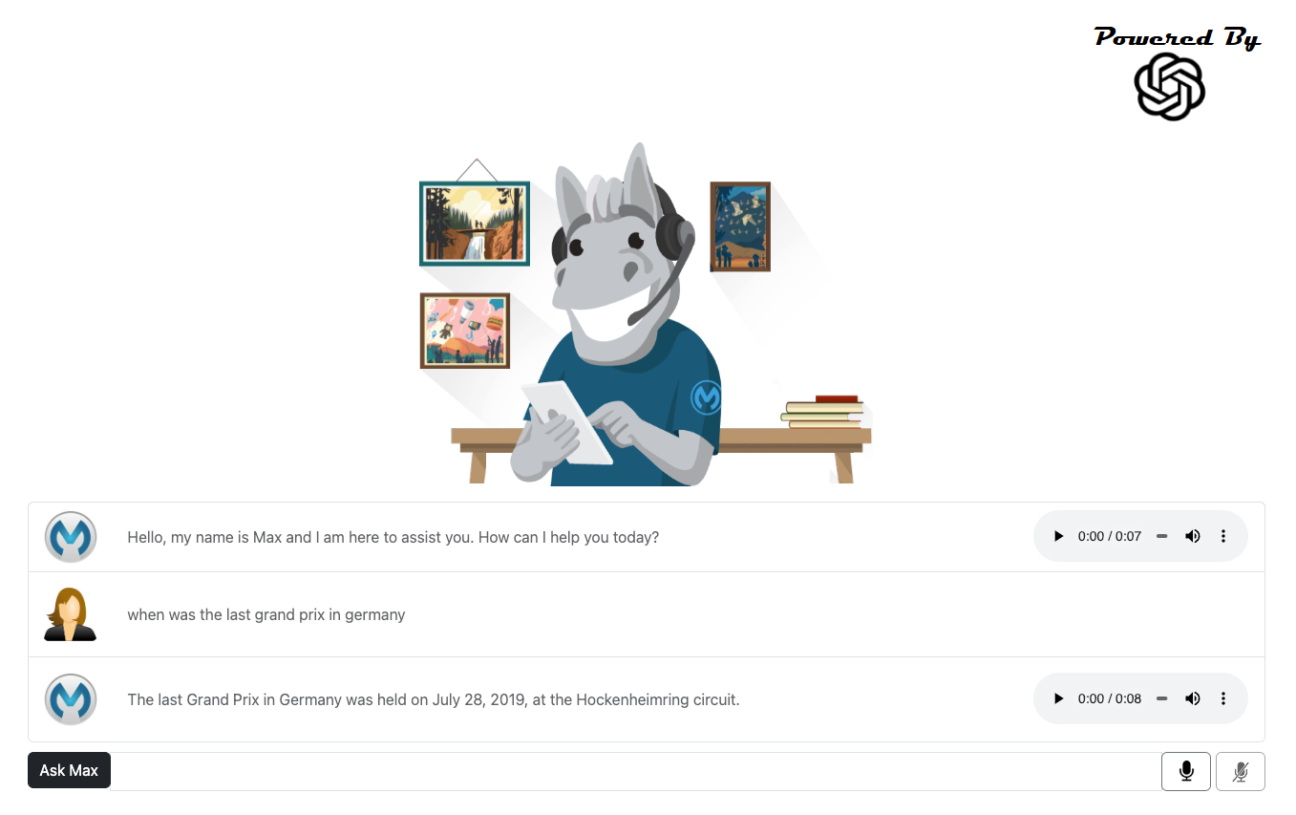
The Grand Prix race the chatbot is referring to here was back in 2019 – its information doesn’t appear to be completely up-to-date. But having read the Whitepaper, you’ll know that LLMs are trained on existing data with a cut-off date. ChatGPT’s training cut-off was towards the end of 2019, which makes sense considering the answer given.
There are ways to overcome this by giving LLMs access to additional data processing tools and more recent data. This will be discussed again later on.
Conversation History
A critical feature of any chatbot is its ability to keep the conversation’s context as it progresses. And as stated earlier, this is possible by re-submitting the conversation history on each interaction.
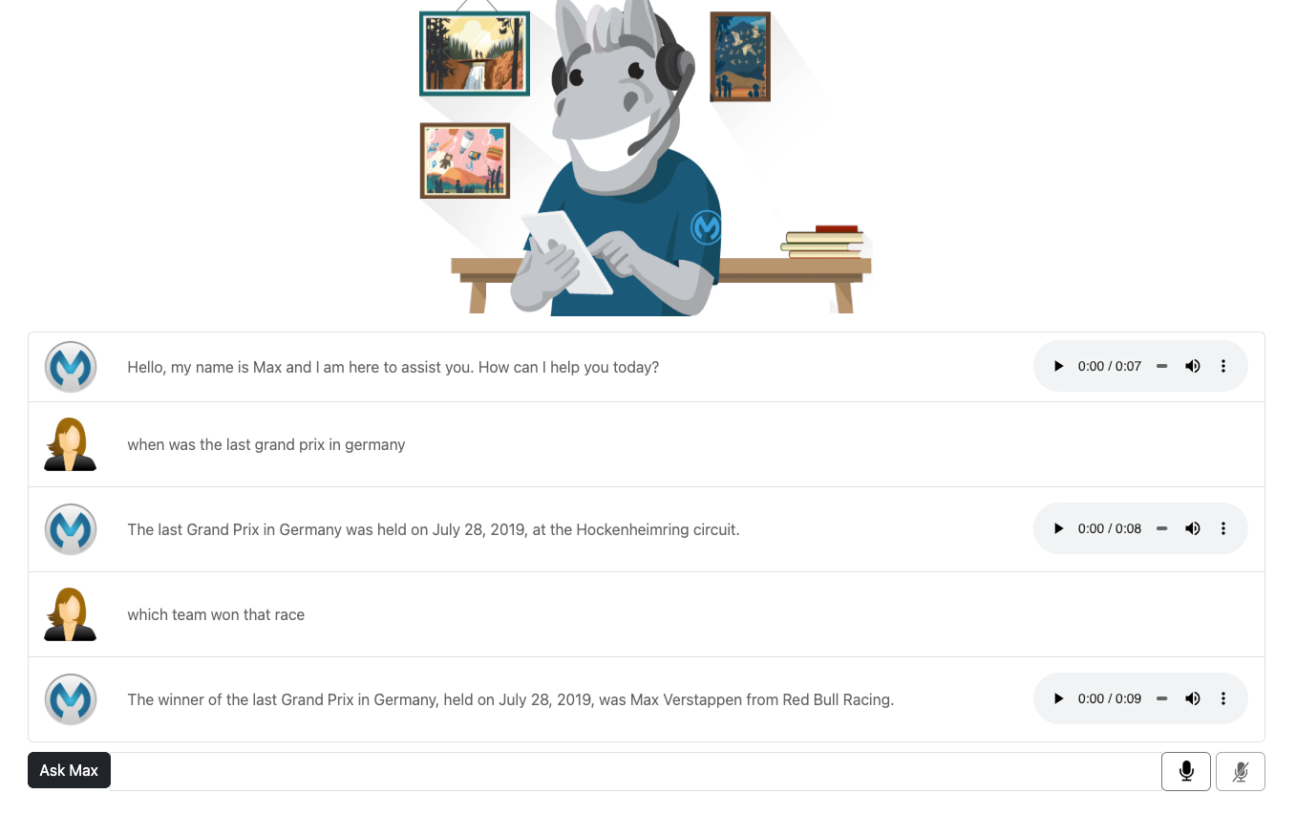
Remember, the resubmission of the complete conversation has implications, and there is a limit. However, there are ways to reduce this impact – such as dropping older interactions (probably not needed as the conversation has progressed) or only keeping track of the chatbot’s responses (this will generally be sufficient to give a good overview of the conversation).
However, in this PoC, the whole conversation history is retained. For this, a Key-Value store is the appropriate solution, and MuleSoft has one available, the Object Store.
Spoken Input
The final interesting aspect of the chatbot is its ability to take verbal input directly from the microphone. There are multiple ways of doing this, but for this PoC, there are simple buttons for turning the microphone on and off (bottom right of the screen).
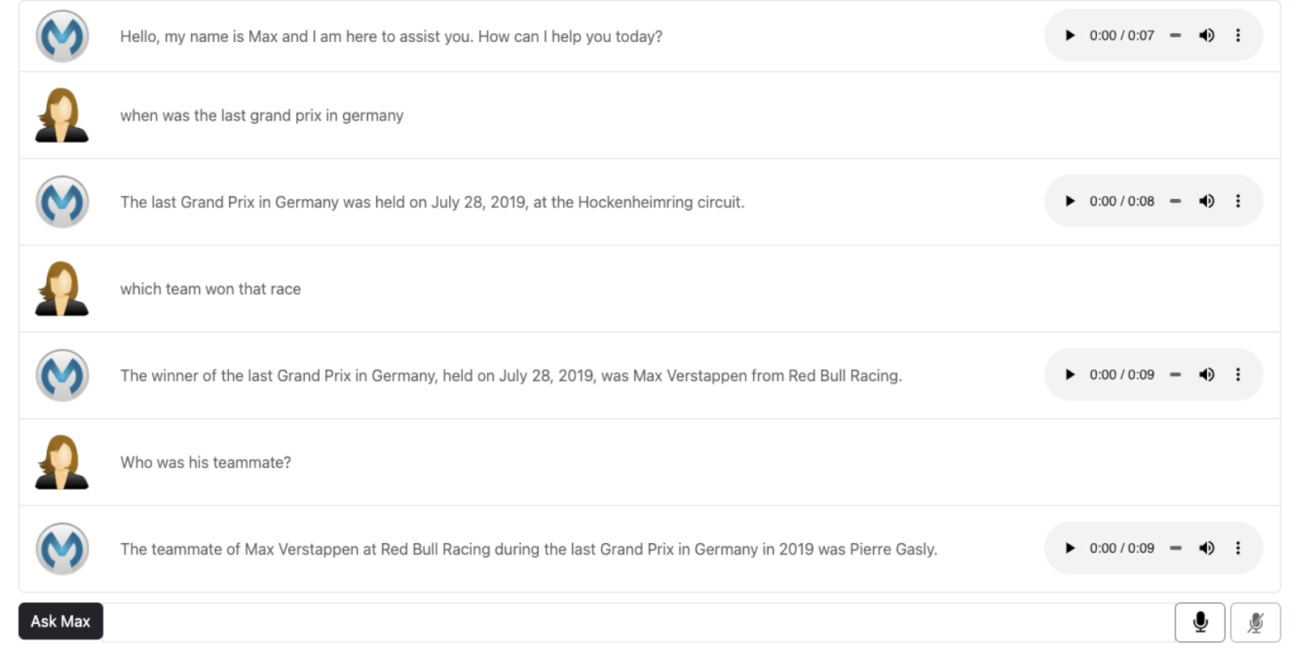
Remember, the chatbot uses OpenAI’s Whisper service to transcribe the spoken words. Notice that not only can it discern each word, but it can add correct punctuation – such as Question Marks.
One final point is that the answer to the last question is wrong, referred to as a hallucination – the LLM has made up the answer. This is a fundamental flaw with generative AI and has to be taken seriously. However, many articles refer to this subject and ways to mitigate against it – more focused prompts, additional training, etc.
Alexa Skills
The chatbot now runs happily from a Web Browser. However, the final aspect of this PoC was accessing it from a Personal Assistant device. The GUI itself cannot run on a device. Still, as MuleSoft’s approach of API-Led Connectivity has been used, all that needs to be done is build an Alexa Skill to access the APIs within the Application Network. Below is the same conversation as above but from Alexa.
The following screenshot is taken from the Alexa Skills Developer Console.
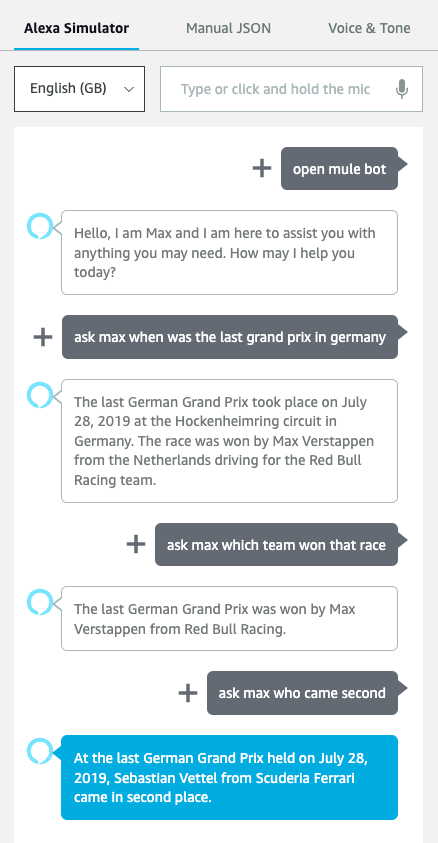
The first Command, open mule bot, is required to open the Alexa Skill (named ‘mule bot’). Then, each question is prefixed with the Command ask max to inform the Skill that a question is being asked.
Conclusion
Did we complete the brief of integrating MuleSoft with OpenAI and building an intelligent chatbot?
Well the complete chatbot can be accessed from both a Web Browser and a Personal Assistant device. So I would say the Brief has been met. But this was only a PoC. What additional enhancements could be added in the future?
Next Steps
The most apparent enhancement (and probably the simplest) is to allow for further customisation to the responses from ChatGPT; many default settings were chosen for this PoC. Though, several parameters can be passed in with a user’s prompt, such as temperature, which can be used to tune the creativity and randomness of the response.
Another enhancement would be to replace the Object Store with a database (such as MongoDB) depending on whether the extra features and functionality of a complete NOSQL database would be helpful.
The final improvement to mention (and would be obligatory if this PoC were to be developed further) would be to allow multiple users to access the chatbot simultaneously. Currently, only one user can use the chatbot at any time, and the current retention of the conversation history reflects this. For multiple users, each conversation must be distinguishable from all other discussions. This could be done by giving each user a unique ID to be embedded in the key of the conversation database.
So we’ve finished, and Yes, this has been a fun, technical challenge, and it demonstrates that it is possible to integrate with this technology, but is there any actual use to it? We must first understand what is happening in this sector to answer this question.
Unstoppable AI
Advances in Conversational AI and Natural Language Processing are exceptionally rapid at the moment – new progress is seemingly being documented each week (for both good and bad). For example, OpenAI’s GPT-3.5, which was only released at the end of last year, has already been superseded by GPT-4 (a model that’s much more sophisticated).
OpenAI has also recently introduced the ability to build Plugins for ChatGPT, allowing access to third-party applications (such as internet search capabilities and computational functionality). Note that Plugin development is still in the early stages but will considerably increase the usefulness of LLMs and solutions built upon them.
Python-based projects, such as LlamaIndex and LangChain, provide similar capabilities extending the reach and capabilities of LLMs even further.
Privacy concerns and ethical questions are continually highlighted and debated, with new policies being written and reworked. Fully open-source LLM variants are being developed, giving broader access and demanding reduced hardware requirements for running. All of which aim to combat the exclusive and closed nature of the technology.
Final Thoughts
So, to answer whether such technology is of actual use. The answer is Yes. It’s becoming possible to build solutions that allow LLMs to access data far beyond their initial training input, giving them access to up-to-date and non-public data.
Consider that many Organisations already hold and retain massive amounts of structured and unstructured data stored in documents, databases and private repositories – all key to their success. This technology is extremely good at tasks such as Summarisation, Extraction and Classification, which are invaluable but can also be utilised further to create Recommendations and perform Sentiment Analysis. These Organisations must start thinking about how AI-driven solutions can support them when challenged to maintain that competitive edge.
By creating new services for internal and external consumption, they can provide value and benefit to consumers at all levels. Achieved through access, analysis, and ultimately from seeing meaningful and valuable insights into their business – all with the help of MuleSoft Integration. Contact us today to see how we can help you with integrating MuleSoft with OpenAI.

